
W dzisiejszym artykule wyposażę Cię w zupełnie nowe podejście do tworzenia aplikacji, które przy odrobinie praktyki sprawi, że Twoje aplikacje staną się mniej złożone, prostsze w implementacji i testowaniu oraz łatwiejsze w utrzymaniu. Brzmi niemożliwie? A jednak! Zapraszam Cię do świata Portów i Adapterów.
Jak czytać ten artykuł
Wytłumaczenie architektury aplikacji jest nie lada wyzwaniem, szczególnie jeśli mamy do pokrycia tak wiele zagadnień jak w przypadku Architektury Hexagonalnej. Dlatego proponuję abyś przeczytał ten artykuł do końca, nawet jeśli coś początkowo będzie w nim niezrozumiałe. Na końcu artykułu znajdziesz link do kolejnego artykułu – tym razem praktycznego. Poprowadzi Cię on krok po kroku przez proces migracji dwóch mikroserwisów napisanych w architekturze warstwowej na Architekturę Hexagonalną. Wówczas omówione w obecnym artykule zagadnienia ułożą się w jedną spójną całość. Dlatego proponuję abyś wrócił do tego artykułu, po zrobieniu części praktycznej celem wyłapania wskazówek, które podczas pierwszego czytania mogły nie wydać się zbyt istotne, ale po zapoznaniu się z całością już takimi się staną.
Wprowadzenie
W świecie IT nie ma ani najlepszego języka programowania ani jednej najlepszej architektury pisania aplikacji. Są to tylko narzędzia, które użyte we właściwym kontekście mogą ułatwić i przyspieszyć naszą pracę. Oczywiście, gdy źle dobierzemy narzędzia do rozwiązania danego problemu, to możemy się spodziewać szybko rosnącego skomplikowania aplikacji, wąskich gardeł wydajnościowych jak również rosnących kosztów utrzymania systemu. Wyobraź sobie teraz, że masz programistę, który słyszał jedynie o architekturze warstwowej i Ciebie – zaznajomionego z wieloma różnymi podejściami. Kto według Ciebie będzie trafniej dobierał rozwiązania?
Moim zdaniem, wywodząca się z DDD(Domain Driven Development) Architektura Heksagonalna to absolutny must have dla senior-deweloperów i projektantów aplikacji, gdyż niejako by design pozwala na uporządkowanie logicznych odpowiedzialności w systemie. Nawet jeśli nie jest to jeszcze dla Ciebie jasne, to gwarantuję, że a chwilę będzie. Aby lepiej zrozumieć co takiego dają nam Porty i Adaptery zacznijmy od przeglądu klasycznej architektury warstwowej.
Architektura warstwowa
Warstwowa architektura aplikacji króluje po dziś jako jedna z najpopularniejszych metod organizacji komponentów w systemach, szczególnie gdy mamy do czynienia z aplikacjami monolitycznymi. W zależności od skali systemu oraz używanych komponentów liczba warstw oraz ich przeznaczenie może się nieco różnić, ale dla uproszczenia można przyjąć, że składa się ona zwykle z następujących warstw:
- Warstwy persystencji (Persistence) – odpowiedzialnej za mapowanie ORM i komunikację z bazą danych
- Warstwa usług biznesowych (Service) – Odpowiedzialnej za kompozycję operacji biznesowych
- Warstwy prezentacji i/lub kontrolera web (Controller) – Odpowiedzialnej za prezentację i/lub eksponowanie usług w przypadku WebService.
Problemy architektury warstwowej
Na pierwszy rzut oka wszystko wygląda ładnie – w jednej warstwie baza, w drugiej logika biznesowa w trzeciej kontrolery web. Więc ktoś może zapyta z czym mam problem. Otóż problem w tym, że to nie jest prawda :). A dokładniej przyjrzyjmy się trzem następującym aspektom: zależności między warstwami, widoczności klas oraz zakresu odpowiedzialności.
Problem 1. Zależność między warstwami
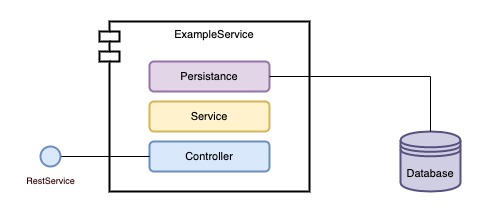
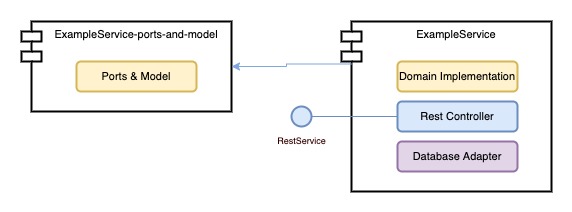
Pierwsza, kwestia, którą chcę poruszyć to zależność między warstwami w aplikacji opartej o architekturę warstwową. Dla lepszego uwidocznienia problemu załóżmy, że mamy do czynienia z monolitem ExampleService, który podzieliliśmy na trzy moduły, w których umieściliśmy każdą z warstw z osobna – to dość częsta praktyka. Na diagramie poniżej zaznaczyłem również zależności między modułami.
Od razu widać, że warstwa usług biznesowych jest świadoma warstwy persystencji, a warstwa kontrolera bezpośrednio ma wiedzę o logice biznesowej oraz pośrednio o szczegółach persystencji. Czy kontroler naprawdę musi mieć wiedzę i dostęp do encji? Nie musi. Ba! Nawet nie powinien. Dodajmy do tego fakt, że warstwa persystencji często korzysta z bibliotek ORM takich jak np. Hibernate, czy wyspecjalizowanych sterowników do bazy danych. Każdy moduł, do którego podłączymy moduł persystencji nagle odziedziczy tę całą wiedzę oraz biblioteki.
Problem 2. Widoczność klas
Jedną z metod organizacji kodu jest umieszczanie go w pakietach(folderach, przestrzeniach nazw) zwykle w celu zgrupowania pewnych odpowiedzialności. Wiele języków programowania umożliwia również kontrolę dostępu pomiędzy klasami czy metodami klas znajdującymi się w różnych pakietach. Przykładowo w Java realizuje się to poprzez użycie modyfikatorów widoczności klas (public, protected i package scope). Wróćmy zatem do naszego przykładu. Naturalną będzie struktura pakietów rozpoczynająca się od jakiegoś prefixu określającego aplikację (np. com.example) w którym znajdują się trzy pakiety określające warstwy aplikacji: persistence, service, controller. Zauważ, że obiekty z warstwy logiki biznesowej potrzebują dostępu do encji z warstwy persystencji. Ponieważ znajdują się one w innym pakiecie niż logika biznesowa, to w zasadzie musimy uczynić je publicznymi. Czyli z grupowania i kontroli dostępu wykorzystujemy w sumie tylko to pierwsze, a w sprawie kontroli ufamy, że inny programista nie wykorzysta luki.
Problem 3. Zakres odpowiedzialności oraz świadomość ekosystemu
Powiedzieliśmy wcześniej, że warstwa logiki biznesowej zawiera – jak nazwa wskazuje – logikę biznesową, ale czy na pewno? Otóż nie do końca. Zawiera ona logikę biznesową, ale również całkiem sporo wiedzy technicznej na temat środowiska, w którym nasza aplikacja egzystuje oraz to w jaki sposób komponenty komunikują się ze sobą. Przeglądając kod warstwy logiki biznesowej natkniemy się bardzo często na wywołanie odczytu z bazy danych, zawołanie jakiegoś WebService i np zapisanie wyniku znów do bazy danych. Problem w tym, że inaczej woła się bazę danych a inaczej np. klienta REST. Czytając kod dosłownie mamy coś takiego „Wczytaj produkt z bazy danych. Wywołaj metodę GET /products/{id} zewnętrznego serwisu REST. Zapisz wynik do bazy danych”, gdzie tak naprawdę wymaganie biznesowe to „Wczytaj produkt. Uzupełnij szczegóły produktu na podstawie informacji z firmowej bazy produktów. Zapisz produkt.”.
Wspomniałem jeszcze o świadomości modułu. Czy jeśli zmienimy protokół pobierania danych o produktach z serwisu REST na SOAP, to czy powinniśmy dokonywać jakiejkolwiek zmiany w module logiki biznesowej. Moim zdaniem nie powinniśmy musieć tego robić. Jednak w przypadku architektury warstwowej będziemy do tego zmuszeni. Podobnie, czy można przystąpić do prac nad implementacją logiki podczas, gdy nie mamy jeszcze decyzji gdzie finalnie w firmie będzie się znajdować centralna baza produktów. Oczywiście można wprowadzić w tym miejscu pewną abstrakcję, ale o tym za moment, ponieważ tu właśnie przechodzimy do Architektury Hexagonalnej.
Architektura Hexagonalna
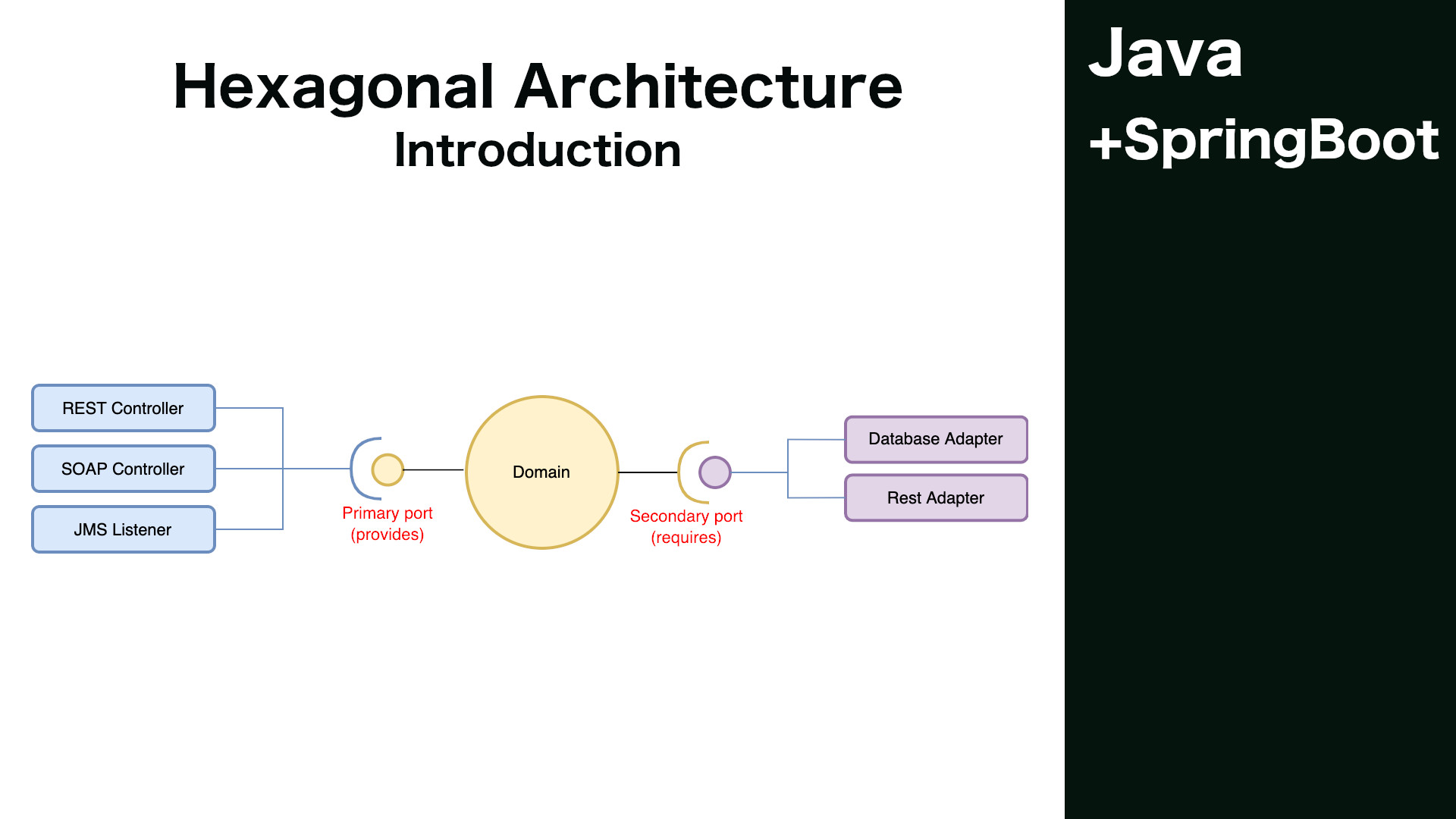
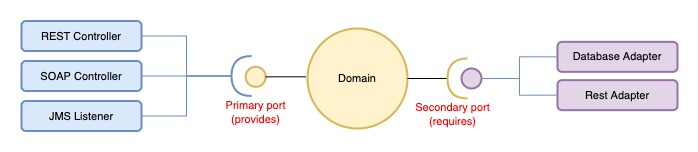
Architektura Hexagonalna zwana również jako „Porty i Adaptery”, to koncepcja zaczerpnięta z Domain Driven Development. Zakłada ona istnienie pewnej Domeny – może być to zarówno domena biznesowa (np. Księgowość), jak również jakaś domena techniczna (np. Wydruki). Domena udostępnia światu pewne usługi poprzez porty (Primary Ports), najczęściej wymagając dostarczenia pewnych informacji z zewnątrz – również poprzez porty (Secondary Ports). Domena, na potrzeby wewnętrzne oraz komunikacji poprzez porty, wprowadza swój własny język(Model), w którym funkcjonują pojęcia specyficzne dla niej. Bardzo ważne na etapie projektowania domeny jest myślenie z jej perspektywy, jej pojęciami oraz wyzbycie się w tym momencie wiedzy o aspektach technicznych. Trzeba to robić tak jakbyś był nową osoba w firmie, a taki proces nigdy wcześniej nie funkcjonował w organizacji. Czyli na nowo trzeba zdefiniować wszystkie pojęcia oraz ewentualnie zweryfikować te istniejące.
Implementacje Secondary Ports znajdują się gdzieś poza domeną i to w nich tłumaczony jest język Domeny na język infrastruktury np. bazy danych czy klienta REST.
Z drugiej strony różnego rodzaju kontrolery w naszej aplikacji(REST, SOAP czy JMS Listener), mogą korzystać dokładnie z tych samych usług udostępnionych w Primary Ports.
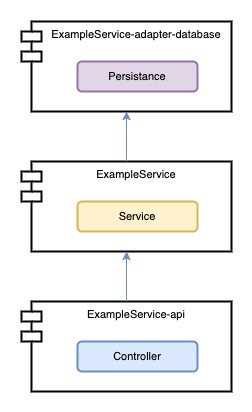
Organizacja kodu w Architekturze Hexagonalnej
Skoro zapoznałeś się już z ogólną koncepcją Portów i Adapterów, to omówmy teraz kilka zasad dotyczących organizacji kodu w aplikacji, tak aby w pełni wykorzystać elastyczność tego podejścia. Przede wszystkie wykorzystamy
Krok 1. Kontrakt Domeny – moduł <DOMAIN_NAME>-ports-and-model
Na początku musimy określić kontrakt naszej domeny. Składa się on z języka, informacji o świadczonych usługach oraz usługach, które domena wymaga od świata zewnętrznego – czyli Modelu oraz Primary Ports i Secondary Ports. Tak przygotowany kontrakt czynimy publicznym i pakujemy w moduł <DOMAIN_NAME>-ports-and-model. Zauważ, że poprzez wydzielenie kontraktu sprawiło, że kolejne kroki, czyli implementacje Domeny i adapterów, mogą już być wykonywane równolegle przez różne zespoły programistów, Mało tego! Mogą to robić w jednym lub zupełnie w osobnych modułach. Posiadając wiedzę o kontrakcie nie muszą nawet wiedzieć o istnieniu pozostałych zespołów aby zaimplementować swoją część. To właśnie największa zaleta Architektury Hexagonalnej, czyli wiesz tyle ile trzeba – nic ponad to.
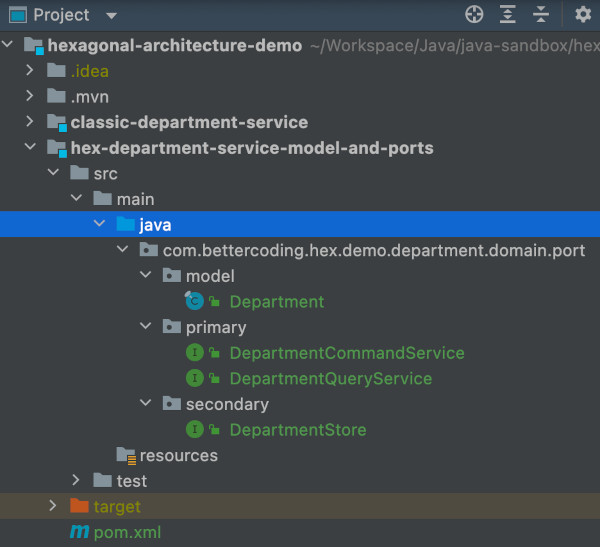
Proponuję aby strukturę pakietów przyjąć jak w poniższym przykładzie, czyli do bazowego pakietu (w moim przypadku „com.bettercoding.hex.demo.department„) zbudować strukturę domain.port.[model|primary|secondary].
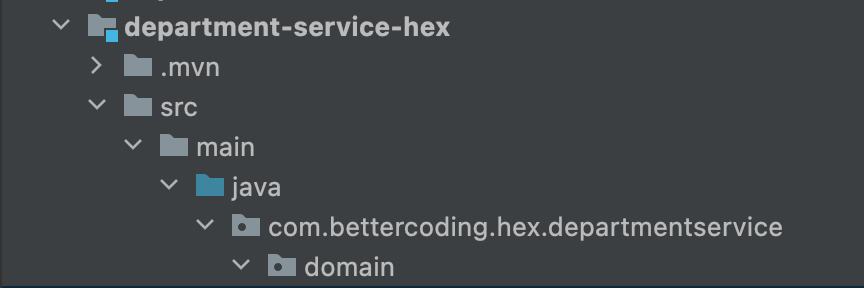
Zwróć uwagę na to, że wszystkie klasy i interfejsy mają widoczność publiczną. Dodatkowo primary port podzielony został na dwa interfejsy CommandService oraz QueryService. W ten sposób wprowadzamy CQS(Command Query Segregation) w Architekturze Hexagonalnej. Warto tu wspomnieć, że komendy mogą przyjmować parametry, ale nie zwracają wartości, Jeśli chodzi o QueryService, to jej metody mogą przyjmować parametry i muszą zwracać wynik.
Mając zdefiniowany kontrakt możemy przystąpić do implementacji domeny oraz adapterów. W zasadzie mogą to robić równolegle dwa lub nawet więcej zespołów – np. jeden odpowiedzialny za przygotowanie kontrolerów REST a drugi za adaptery bazodanowe.
Krok 2. Implementacja Domeny – moduł <DOMAIN_NAME>
Mimo, że nie jest to krok konieczny, to w naszym przykładzie domenę zaimplementujmy w osobnym module aby dokładnie zobrazować zależności między portami, domeną oraz adapterami.
Implementację domeny zacznijmy zatem od utworzenia nowego modułu maven o nazwie <DOMAIN_NAME>. Następnie dodaj do niego zależność do kontraktu, czyli do modułu <DOMAIN_NAME>-ports-and-model. Proponuję aby jw tym momencie przygotować strukturę pakietów jak na poniższym przykładzie, czyli do bazowego pakietu (w moim przypadku „com.bettercoding.hex.demo.department„) dodaj pakiet domain.
Mając przygotowaną strukturę pakietów możemy przejść do implementacji logiki biznesowej domeny. W tym poradniku kładę nacisk na zarysowanie Ci ogólnej koncepcji architektury heksagonalnej bez wchodzenia w szczegóły, w związku z tym nasza logika biznesowa również będzie bardzo prosta. W naszym przypadku mamy dostarczyć implementacji dwóch usług saveDepartment oraz findDepartmentById. Możemy je dostarczyć np. za pomocą poniższej implementacji DepartmentService.
package com.bettercoding.hex.departmentservice.domain;
import com.bettercoding.hex.departmentservice.domain.port.dto.Department;
import com.bettercoding.hex.departmentservice.domain.port.primary.DepartmentCommandService;
import com.bettercoding.hex.departmentservice.domain.port.primary.DepartmentQueryService;
import com.bettercoding.hex.departmentservice.domain.port.secondary.DepartmentStore;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
@Service
@RequiredArgsConstructor
class DepartmentService implements DepartmentQueryService, DepartmentCommandService {
private final DepartmentStore departmentStore;
@Override
public void saveDepartment(Department department) {
this.departmentStore.saveDepartment(department);
}
@Override
public Department findDepartmentById(String departmentId) {
return this.departmentStore.findDepartmentById(departmentId);
}
}
Omówmy pokrótce kod logiki domenowej. Na początek warto zwrócić uwagę, że zadaniem klas z pakietu domain jest dostarczenie implementacji metod wyeksponowanych w PrimaryPort’ach wykorzystując jedynie logikę domenową oraz informacje pozyskane z SecondaryPort’ów. W naszym przypadku owa logika to jedynie zawołanie departmentStore.saveDepartment oraz departmentStore.findDepartmentById, czyli wprost zapisz lub wyszukaj w store dany department. Wyobraźmy sobie jednak, że pojawia się wymaganie „Podczas tworzenia departamentu, należy poprawić nazwę departamentu taką aby składała się one tylko z małych liter„. Taka logika jak najbardziej powinna zostać umiejscowiona w metodzie saveDepartment, co zostało pokazane poniżej.
package com.bettercoding.hex.departmentservice.domain;
import com.bettercoding.hex.departmentservice.domain.port.dto.Department;
import com.bettercoding.hex.departmentservice.domain.port.primary.DepartmentCommandService;
import com.bettercoding.hex.departmentservice.domain.port.primary.DepartmentQueryService;
import com.bettercoding.hex.departmentservice.domain.port.secondary.DepartmentStore;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
@Service
@RequiredArgsConstructor
class DepartmentService implements DepartmentQueryService, DepartmentCommandService {
private final DepartmentStore departmentStore;
@Override
public void saveDepartment(Department department) {
Department newDepartment = new Department(department.getId(), department.getName().toLowerCase());
this.departmentStore.saveDepartment(newDepartment);
}
@Override
public Department findDepartmentById(String departmentId) {
return this.departmentStore.findDepartmentById(departmentId);
}
}
Opatrzenie naszej klasy adnotacją @Service sprawia, że rejestrujemy ją w kontekście Springa dostarczając implementacji dla interfejsów DepartmentQueryService, DepartmentCommandService. Zwróć proszę uwagę, że owe interfejsy są publiczne a klasa je implementująca ma jedynie zasięg pakietowy, co w praktyce oznacza, że nikt nie użyje klasy DepartmentService w innym celu niż została zaimplementowana.
Krok 3. Implementacja Adapterów – moduł app-infrastructure
Ostatnimi elementami układanki, które pozostały nam do zaimplementowania są adaptery oraz konfiguracja infrastruktury. W naszym przypadku będą to adaptery w postaci kontrolera REST oraz adapter komunikujący się z baza danych za pomocą JPA. Pierwszy z nich posłuży nam do wyeksponowania usług saveDepartment oraz findDepartmentById na świat. Drugi będzie odpowiedzialny za zapis/odczyt do/z bazy danych. Konfiguracja infrastruktury odpowiada natomiast za sklejenie naszej aplikacji w całość, czyli dostarczenie implementacji SecondaryPort’ów poprzez przekierowanie ich do modułów technicznych. Ten wątek szczegółowo omówimy w dedykowanym poradniku. Póki co uprościmy nieco ten przykład łącząc ze sobą konfigurację oraz adapter w jedno.
W naszym przykładzie zarówno adaptery REST, adaptery DB oraz konfiguracja znajdować się będą w jednym module – głównym module aplikacji.
Zacznijmy od przygotowania struktury pakietów dla naszej infrastruktury. Do bazowego pakietu (w moim przypadku „com.bettercoding.hex.demo.department„) dodajemy strukturę infrastructure.adapter.[primary.rest|secondary.db].
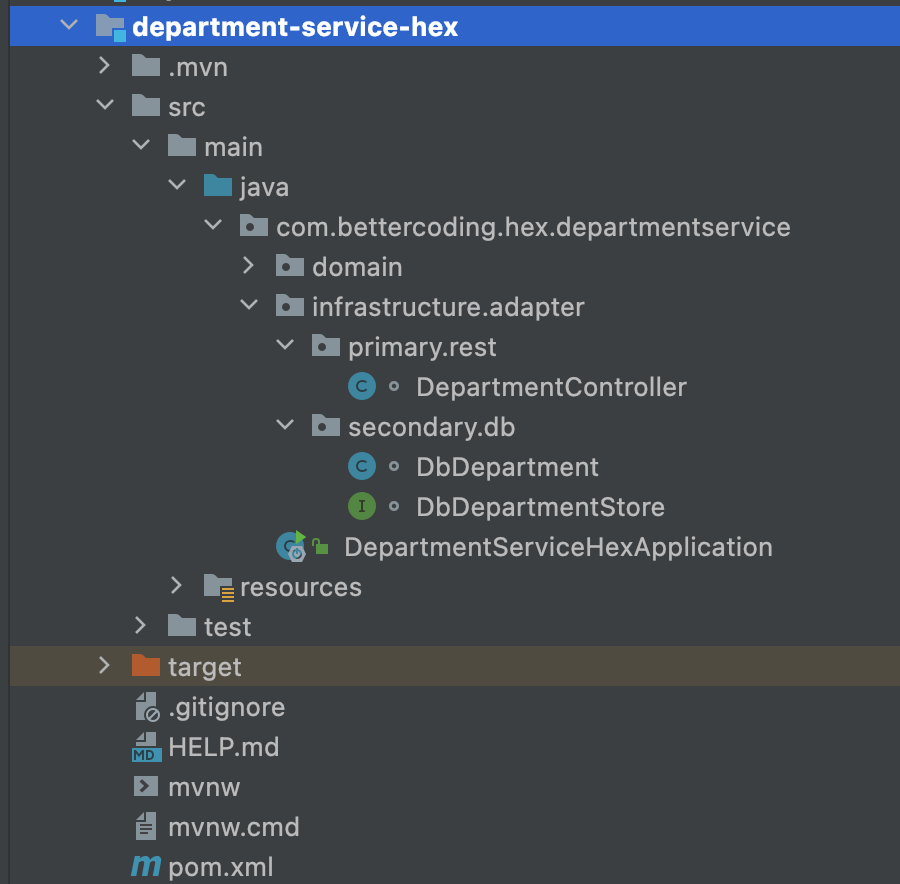
Mając przygotowaną strukturę pakietów możemy przejść do implementacji kontrolera REST. Jak zapewne zauważyłeś – nie jest on zbyt skomplikowany. Najważniejsze, na co należy zwrócić uwagę, to fakt, że w kontrolerze korzystamy z PrimaryPort’ów domeny, czyli interfejsów: DepartmentCommandService oraz DepartmentQueryService.
package com.bettercoding.hex.departmentservice.infrastructure.adapter.primary.rest;
import com.bettercoding.hex.departmentservice.domain.port.dto.Department;
import com.bettercoding.hex.departmentservice.domain.port.primary.DepartmentCommandService;
import com.bettercoding.hex.departmentservice.domain.port.primary.DepartmentQueryService;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/departments")
@RequiredArgsConstructor
class DepartmentController {
private final DepartmentCommandService departmentCommandService;
private final DepartmentQueryService departmentQueryService;
@PostMapping("/")
public void saveDepartment(@RequestBody Department department) {
this.departmentCommandService.saveDepartment(department);
}
@GetMapping("/{departmentId}")
public Department findDepartmentById(@PathVariable("departmentId") String departmentId) {
return this.departmentQueryService.findDepartmentById(departmentId);
}
}
Następnie przechodzimy do implementacji adaptera bazy danych, W tym celu przygotowujemy encję DbDepartment oraz repozytorium DbDepartmentStore będące również implementacją naszego store’a. W klasie DDepartmentStore implementujemy wymagane metody z interfejsu DepartmentStore posiłkując się wewnętrznie zdefiniowanym mapperem DepartmentMapper.
package com.bettercoding.hex.departmentservice.infrastructure.adapter.secondary.db;
import com.bettercoding.hex.departmentservice.domain.port.dto.Department;
import com.bettercoding.hex.departmentservice.domain.port.secondary.DepartmentStore;
import org.mapstruct.Mapper;
import org.mapstruct.factory.Mappers;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
interface DbDepartmentStore extends JpaRepository<DbDepartment, String>, DepartmentStore {
DepartmentMapper DEPARTMENT_MAPPER = Mappers.getMapper(DepartmentMapper.class);
@Override
default void saveDepartment(Department department){
this.save(DEPARTMENT_MAPPER.toDbDepartment(department));
}
@Override
default Department findDepartmentById(String departmentId) {
return DEPARTMENT_MAPPER.toDepartment(this.getById(departmentId));
}
@Mapper
interface DepartmentMapper {
Department toDepartment(DbDepartment dbDepartment);
DbDepartment toDbDepartment(Department department);
}
}
package com.bettercoding.hex.departmentservice.infrastructure.adapter.secondary.db;
import lombok.Getter;
import lombok.Setter;
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
@Getter
@Setter
class DbDepartment {
@Id
private String id;
private String name;
}
Podsumowanie
Zalety architektury heksagonalnej
- Enkapsulacja domen poprzez stosowanie minimalnego zakresu widoczności – zauważ, że w architekturze heksagonalnej niemal wszystkie obiekty poza portami i modelem mają co najwyżej zasięg pakietowy.
- Możliwość testowania logiki biznesowej w oderwaniu do aspektów technicznych tj. baza danych.
- Możliwość równoległego budowania modułów projektu – projekty model-and-ports budują się równolegle, następnie równolegle budują się projekty domen i infrastruktury a na koniec budują się moduły spinające aplikację, czyli konfiguracja i moduł aplikacji spring.
- W łatwy sposób pozwala na segregację odpowiedzialności klas i modułów, dzięki czemu łatwiej również o identyfikację miejsca, w którym należy zaimplementować nowy kod lub poprawić istniejący.
Wady architektury heksagonalnej
- Stosunkowo dużo mapowań obiektów bardzo podobnych do siebie (np. DTO żądania REST na DTO domeny)
- Ze względu na dużą liczbę mapowań zmiany w szerz aplikacji (np. dodanie nowego atrybutu do szerokoużywanego DTO) może powodować zmiany w wielu miejscach.
- Rozwiązania nie zawsze są optymalne – ponieważ myślimy z perspektywy domeny, to trudniej jest zastosować/zauważyć pewne optymalizacje. Np. Filtrowanie zbioru wierszy można wykonać szybciej w adapterze bazy danych poprzez dedykowane zapytanie niż wołając findAll() i następnie filtrować wyniki w JAVA.

