

In the following article, apart from providing two solutions to the title problem, we will also talk about a few side topics. I find them worth discussing as they explain the specific behavior of SpringBoot and the H2 database when running JUnit tests.
TL;DR
You can find a ready to use solution here and on my GitLab. However, I encourage you to read the whole article, because when coming up with the solution, I add many interesting digressions from the field of SpringBoot and the H2 database itself.
Why clean the database at all during testing?
Resetting the database state before running each test can be very useful when dealing with integration tests and Spring. Very often, in the case of integration tests, we use the in-memory H2 database, which allows us to test the JPA layer with a real database. The problem is that this instance of the database is run together with the Spring context being raised and it stores its state until the application is turned off. This causes problems with determining the state of the database before starting a given test and whether the state state does not affect the test result. Therefore, it would be much more convenient to clean the database before running each test case, to make sure that it executes under the same conditions every time. In the following, I will introduce two methods of resetting the database state and discuss the pros and cons of each.
Sample test case
To better illustrate the described problem, I have prepared the following test. Notice that we have two test methods in it. Each of them adds a book to the book repository and checks that there is exactly one book in the repository after each test case.
package com.bettercoding.h2databasecleanup;
import com.bettercoding.h2databasecleanup.db.Book;
import com.bettercoding.h2databasecleanup.helper.BookRepositoryHelper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.UUID;
import static org.junit.jupiter.api.Assertions.assertEquals;
@SpringBootTest
class H2DatabaseCleanupTests {
@Autowired
private BookRepositoryHelper bookRepositoryHelper;
@Test
void firstTest() {
//given
Book book = new Book(UUID.randomUUID().toString(), "A Passage to India", "E.M. Foster");
//when
bookRepositoryHelper.addBook(book);
// then
assertEquals(1, bookRepositoryHelper.findAllBooks().size());
}
@Test
void secondTest() {
//given
Book book = new Book(UUID.randomUUID().toString(), "A Revenue Stamp", "Amrita Pritam");
//when
bookRepositoryHelper.addBook(book);
// then
assertEquals(1, bookRepositoryHelper.findAllBooks().size());
}
}
package com.bettercoding.h2databasecleanup.helper;
import com.bettercoding.h2databasecleanup.db.Book;
import com.bettercoding.h2databasecleanup.db.BookRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.transaction.Transactional;
import java.util.List;
@Component
public class BookRepositoryHelper {
@Autowired
BookRepository bookRepository;
@Transactional
public void addBook(Book book) {
bookRepository.save(book);
}
@Transactional
public List<Book> findAllBooks() {
return bookRepository.findAll();
}
}
package com.bettercoding.h2databasecleanup.db;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import javax.annotation.processing.Generated;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
@Getter
@Setter
@NoArgsConstructor
@Entity
@AllArgsConstructor
public class Book {
@Id
private String id;
@Column
private String title;
@Column
private String author;
}
package com.bettercoding.h2databasecleanup.db;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface BookRepository extends JpaRepository<Book, String> {
}
After running the test, it turns out that the second test case fails, because in the repository, apart from the newly added book, there is another one – added in the first test case. Of course, we can write this test in such a way that it is resistant to the already existing data, but in the case of more complex tests, it is more convenient to start with a clean application and create exactly the conditions we want.
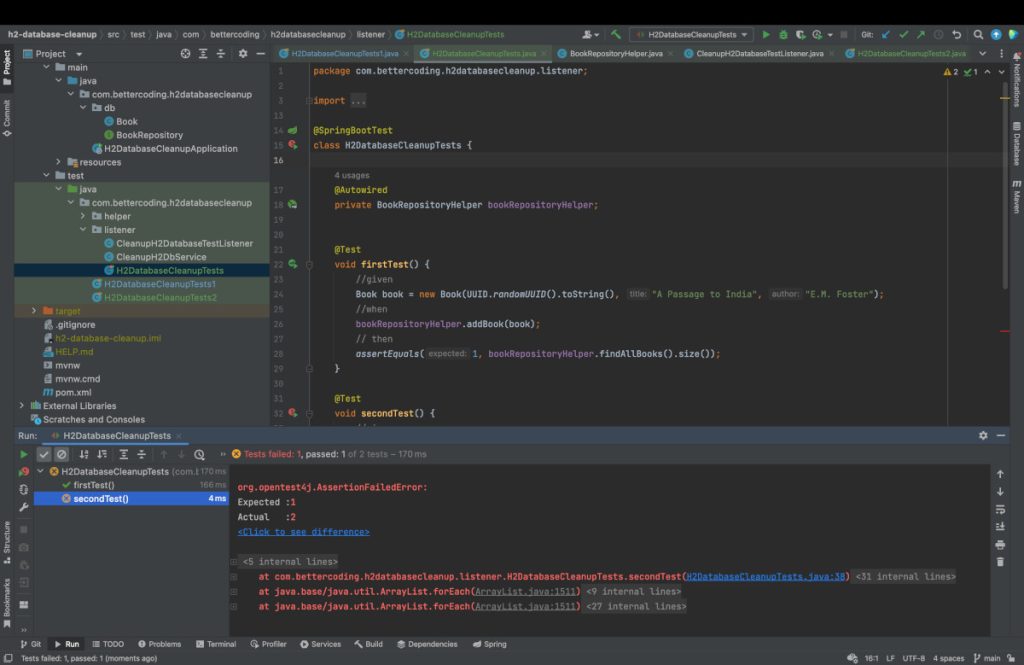
1st Method: @DirtiestContext
SpringBoot has implemented a mechanism of reusing contexts for testing purposes. I will not deep into its detailed description here because out of the scope of this article. It is important to know that if a test class does not differ significantly from another (e.g. it does not have additional beans or other configuration elements), SpringBoot can very quickly deliver a clean copy of the context from a special cache instead of restarting the entire application. In our example, we are dealing with exactly this situation, so SpringBoot will start the context when running the first test case, add it to the cache and then execute the first test case. When the second test case runs, SpringBoot will provide us with a clean copy of the context from the cache – which is a very quick operation – instead of restarting the entire application. Unfortunately, the H2 database is not being re-created.
We can force SpringBoot not to use this context caching mechanism by adding the @DirtiestContext annotation to the test class. It is also important to force a new context to be started for each test case by adding @DirtiesContext (classMode = DirtiesContext.ClassMode.BEFORE_EACH_TEST_METHOD).
package com.bettercoding.h2databasecleanup;
import com.bettercoding.h2databasecleanup.db.Book;
import com.bettercoding.h2databasecleanup.helper.BookRepositoryHelper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.annotation.DirtiesContext;
import java.util.UUID;
import static org.junit.jupiter.api.Assertions.assertEquals;
@SpringBootTest
@DirtiesContext(classMode = DirtiesContext.ClassMode.BEFORE_EACH_TEST_METHOD)
class H2DatabaseCleanupTests1 {
@Autowired
private BookRepositoryHelper bookRepositoryHelper;
@Test
void firstTest() {
//given
Book book = new Book(UUID.randomUUID().toString(), "A Passage to India", "E.M. Foster");
//when
bookRepositoryHelper.addBook(book);
// then
assertEquals(1, bookRepositoryHelper.findAllBooks().size());
}
@Test
void secondTest() {
//given
Book book = new Book(UUID.randomUUID().toString(), "A Revenue Stamp", "Amrita Pritam");
//when
bookRepositoryHelper.addBook(book);
// then
assertEquals(1, bookRepositoryHelper.findAllBooks().size());
}
}
This solution is very easy to implement. Unfortunately, for each test case, the application is restarted, which, depending on the complexity of the application, may take from seconds to several dozen seconds. This may result in extending the test execution time to minutes or even hours. Please pay attention to the execution times of both test cases, which we will compare with the second discussed method.
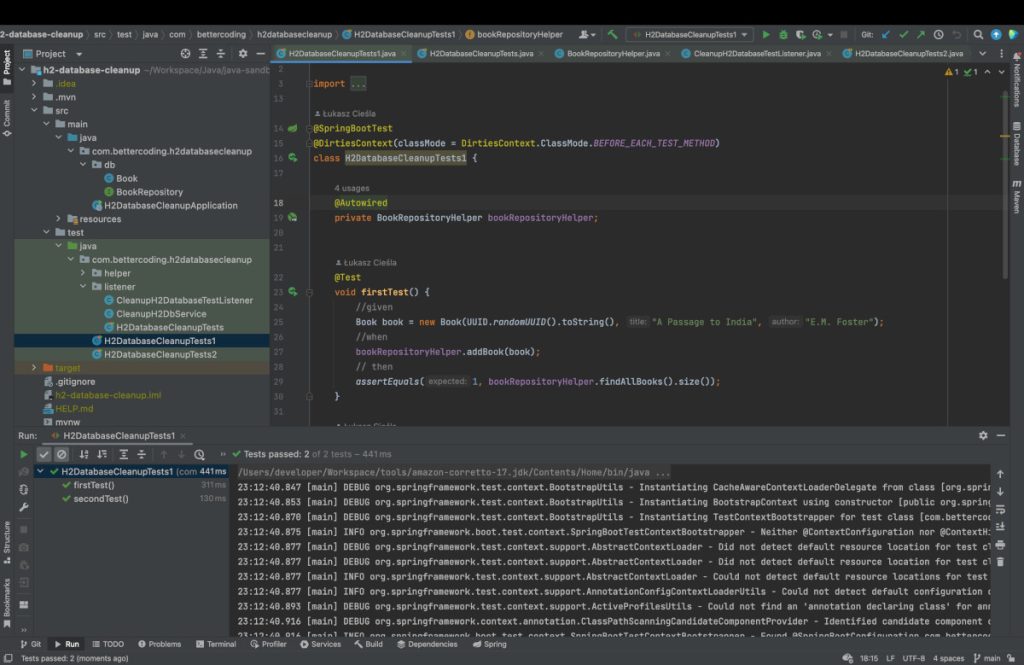
2nd Method: TestExecutionListener that cleans database on every test case
Let’s consider another way to reset the database state before running each test case, so as not to sacrifice the benefits of context caching. Here, the TestExecutionListener interface and the @TestExecutionListeners annotation come in handy, which allows you to connect to the JUnit test execution cycle and run your own code, e.g. before running a test case.
In the following, you will see the source code for the two CleanupH2DatabaseTestListener and CleanupH2DbService classes. The first one is responsible for joining the test execution cycle in such a way as to call the code responsible for cleaning the database, which was implemented in the CleanupH2DbService component. The discussed solution can be presented as follows:
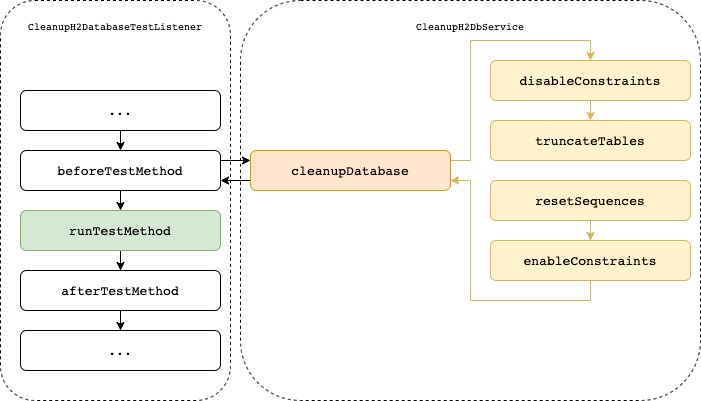
There is one important problem in the process of deleting data in a relational database. Namely, we cannot delete the parent row as long as there are rows that refer to it. In practice, this means cleaning tables in the right order (in the case of a foreign key to the same table, it is even necessary to delete the rows in the right order).
Fortunately, we can use a trick to disable Constraint checking for a moment, so we will be able to delete the data in any order. After deletion is complete, turn on Constraint checking again. An additional step worth taking is resetting all sequences.
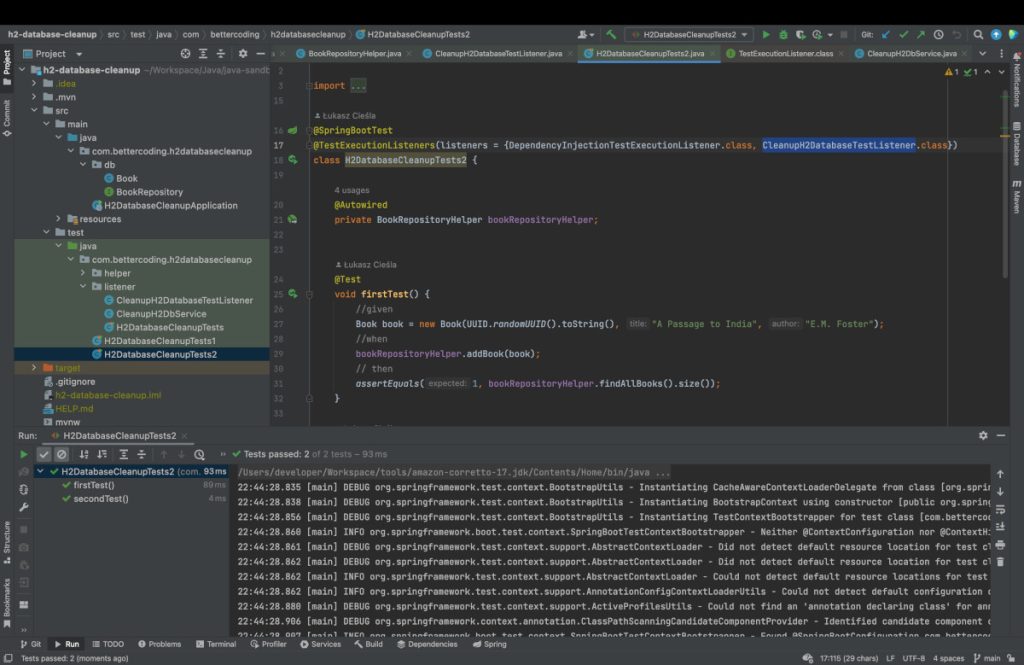
The last thing that remains for us to do is add the newly-implemented CleanupH2DatabaseTestListener to our test using the @TestExecutionListeners annotation. There is also a small catch here – we have to add DependencyInjectionTestExecutionListener to the list of custom listers. In other case Dependency Injection doesn’t work anymore in test. So let’s see the final solution that can also be found on my GitLab.
package com.bettercoding.h2databasecleanup.listener;
import lombok.extern.slf4j.Slf4j;
import org.springframework.core.Ordered;
import org.springframework.test.context.TestContext;
import org.springframework.test.context.TestExecutionListener;
@Slf4j
public class CleanupH2DatabaseTestListener implements TestExecutionListener, Ordered {
private static final String H2_SCHEMA_NAME = "PUBLIC";
@Override
public void beforeTestMethod(TestContext testContext) throws Exception {
TestExecutionListener.super.beforeTestMethod(testContext);
cleanupDatabase(testContext);
}
private void cleanupDatabase(TestContext testContext) {
log.info("Cleaning up database begin");
CleanupH2DbService cleanupH2DbService = testContext.getApplicationContext().getBean(CleanupH2DbService.class);
cleanupH2DbService.cleanup(H2_SCHEMA_NAME);
log.info("Cleaning up database end");
}
@Override
public int getOrder() {
return 0;
}
}
package com.bettercoding.h2databasecleanup.listener;
import lombok.RequiredArgsConstructor;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import javax.sql.DataSource;
import javax.transaction.Transactional;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.HashSet;
import java.util.Set;
@Component
@Slf4j
@RequiredArgsConstructor
public class CleanupH2DbService {
public static final String H2_DB_PRODUCT_NAME = "H2";
private final DataSource dataSource;
@SneakyThrows
@Transactional(Transactional.TxType.REQUIRES_NEW)
public void cleanup(String schemaName) {
try (Connection connection = dataSource.getConnection();
Statement statement = connection.createStatement()) {
if (isH2Database(connection)) {
disableConstraints(statement);
truncateTables(statement, schemaName);
resetSequences(statement, schemaName);
enableConstraints(statement);
} else {
log.warn("Skipping cleaning up database, because it's not H2 database");
}
}
}
private void resetSequences(Statement statement, String schemaName) {
getSchemaSequences(statement, schemaName).forEach(sequenceName ->
executeStatement(statement, String.format("ALTER SEQUENCE %s RESTART WITH 1", sequenceName)));
}
private void truncateTables(Statement statement, String schemaName) {
getSchemaTables(statement, schemaName)
.forEach(tableName -> executeStatement(statement, "TRUNCATE TABLE " + tableName));
}
private void enableConstraints(Statement statement) {
executeStatement(statement, "SET REFERENTIAL_INTEGRITY TRUE");
}
private void disableConstraints(Statement statement) {
executeStatement(statement, "SET REFERENTIAL_INTEGRITY FALSE");
}
@SneakyThrows
private boolean isH2Database(Connection connection) {
return H2_DB_PRODUCT_NAME.equals(connection.getMetaData().getDatabaseProductName());
}
@SneakyThrows
private void executeStatement(Statement statement, String sql) {
statement.executeUpdate(sql);
}
@SneakyThrows
private Set<String> getSchemaTables(Statement statement, String schemaName) {
String sql = String.format("SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES where TABLE_SCHEMA='%s'", schemaName);
return queryForList(statement, sql);
}
@SneakyThrows
private Set<String> getSchemaSequences(Statement statement, String schemaName) {
String sql = String.format("SELECT SEQUENCE_NAME FROM INFORMATION_SCHEMA.SEQUENCES WHERE SEQUENCE_SCHEMA='%s'", schemaName);
return queryForList(statement, sql);
}
@SneakyThrows
private Set<String> queryForList(Statement statement, String sql) {
Set<String> tables = new HashSet<>();
try (ResultSet rs = statement.executeQuery(sql)) {
while (rs.next()) {
tables.add(rs.getString(1));
}
}
return tables;
}
}
package com.bettercoding.h2databasecleanup;
import com.bettercoding.h2databasecleanup.db.Book;
import com.bettercoding.h2databasecleanup.helper.BookRepositoryHelper;
import com.bettercoding.h2databasecleanup.listener.CleanupH2DatabaseTestListener;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.TestExecutionListeners;
import org.springframework.test.context.support.DependencyInjectionTestExecutionListener;
import java.util.UUID;
import static org.junit.jupiter.api.Assertions.assertEquals;
@SpringBootTest
@TestExecutionListeners(listeners = {DependencyInjectionTestExecutionListener.class, CleanupH2DatabaseTestListener.class})
class H2DatabaseCleanupTests2 {
@Autowired
private BookRepositoryHelper bookRepositoryHelper;
@Test
void firstTest() {
//given
Book book = new Book(UUID.randomUUID().toString(), "A Passage to India", "E.M. Foster");
//when
bookRepositoryHelper.addBook(book);
// then
assertEquals(1, bookRepositoryHelper.findAllBooks().size());
}
@Test
void secondTest() {
//given
Book book = new Book(UUID.randomUUID().toString(), "A Revenue Stamp", "Amrita Pritam");
//when
bookRepositoryHelper.addBook(book);
// then
assertEquals(1, bookRepositoryHelper.findAllBooks().size());
}
}
All that remains is to run the tests and check if the result matches the expected result. Please note how much faster the tests were performed compared to the previous method. Cleaning the database in this case took less than 4ms, which is a great result compared to the previous method which took around 130ms. However, it should be remembered that the first method is the overhead associated with the start of the application and depends on the number and time of loading beans, and the second method depends only on the number of tables and the amount of data. By this I mean that as the application becomes more complex, the first method will slow down significantly, while the second – regardless of conditions – will remain just as fast.
To już wszystko co dla Ciebie przygotowałem w tym poradniku. Udostępnij proszę ten post aby pomóc mi dotrzeć do większego grona odbiorców. Dzięki i do zobaczenia w kolejnym poradniku.


